
通用测试数据生成工具 ZenData 1.2 版本发布
转贴:
最后编辑:薛才杰 于 2020-08-20 14:04:44
4655次查看
ZenData是由 禅道项目管理软件团队推出的一款通用的测试数据生成工具。主要为了解决开发和测试过程中测试数据的生成、维护、解析问题。
ZenData官网: https://zd.im/
自动化测试无论单元测试、接口测试、功能测试都会面临一个挑战,即如何能够做到大规模、工程化的自动化测试。这里面会牵扯到很多方面的技术:测试环境、测试手段、测试资源、测试管理等等,但这里面最最重要的一环是测试数据的管理。ZenData则通过YAML文件,定义了一种简单的数据类型描述语法。使用者不需要对技术有过多了解,通过定义简单的字段取值列表、前缀后缀等配置,即可实现测试数据维护的目的。简洁、高效、灵活,是做单元测试、接口测试、功能自动化测试、性能测试、压力测试、打桩mock的有力帮手。
ZenData通过简单的range定义实现了区间、步长、随机、引用、重复、SQL查询等方式,通过简单的规则可应对各种变化。ZenData只有一个可执行文件,支持HTTP模式,还可以对数据进行反向解析,可以输出txt、json、xml、sql等多种格式。
数据生成相关参数
-d --default 默认的数据格式配置文件。
-c --config 当前场景的数据格式配置文件,可以覆盖默认文件里面的设置。
-o --output 生成的数据的文件名。可通过扩展名指定输出json|xml|sql格式的数据。默认输出原始格式的文本数据。
-n --lines 要生成的记录条数,默认为10条。
-F --field 可通过该参数指定要输出的字段列表,用逗号分隔。 默认是所有的字段。
-t --table 输出格式为sql时,需通过该参数指定要插入数据的表名。
-T --trim 输出的字段去除前后缀,通常用在生成SQL格式的输出。
-H --human 输出可读格式,打印字段名,并使用tab键进行分割。
-r --recursive 递归模式。如不指定,默认为平行模式。平行模式下各个字段独立循环。
递归模式下每个字段的取值依赖于前一字段。可增强数据的随机性。
內置数据查看
-l --list 列出所有支持的数据格式。 -v --view 查看某一个数据格式的详细定义。
从SQL生成数据
-i --input 指定一个schema文件,输出每个表的yaml配置文件。需通过-o参数指定一个输出的目录。 -D --decode 根据指定的配置文件,将通过-i参数指定的数据文件解析成json格式。
HTTP模式
-p --port 在指定端口上运行HTTP服务。可通过http://ip/接口获得JSON格式的数据。服务模式下只支持数据生成。 -b --bind 监听的ip地址,默认监听所有的ip地址。 -R --root 运行HTTP服务时根目录。客户端可调用该根目录下面的配置文件。如果不指定,取zd可执行文件所在目录。
命令行举例
$>zd.exe -d demo\default.yaml -c demo\test.yaml -n 100 -o test.txt # 输出原始格式的数据。 $>zd.exe -d demo\default.yaml -c demo\test.yaml -n 100 -o test.json # 输出json格式的数据。 $>zd.exe -d demo\default.yaml -c demo\test.yaml -n 100 -o test.xml # 输出xml格式的数据。 $>zd.exe -d demo\default.yaml -n 100 -o test.sql -t user # 输出针对user表的insert语句。 $>zd.exe -d demo\default.yaml -n 100 -o test.sql -t user --trim # 输出针对user表的insert语句,去掉前后缀。
配置语法举例
title: zendata数据配置语法说明
desc:
# 文件组成
# zendata以yaml格式的文件来定义各个字段的格式。
# yaml文件整体由文件说明和字段定义两部分组成。
# 文件说明
# title: 标题,可以用简短的文字概要描述该文件定义的数据类型。
# desc: 描述,可以用多行文本来详细描述该文件定义的数据类型,非必选项。
# author: 作者,非必选项。
# version:版本号,非必选项。
# 字段列表
# 字段定义部分都放在fields这个定义里面。
# 一个yaml文件可以包含一个或者多个字段。
# 字段列表以-field定义开始。
# 一个字段可以通过fields属性定义它的子字段。
# 字段定义
# field: 字段名,仅支持英文、数字、下换线和.
# range: 列表范围,最重要的定义。
# loop: 循环次数,可以定义某一字段循环多少次。
# loopfix: 每一次循环时的连接符。
# format: 支持格式化输出。
# prefix: 该字段的前缀。
# postfix: 该字段的后缀。
# length: 该字段的长度。如果不通过分隔符区分,则需要指定字段长度,单位是字节。
# leftpad: 左填充的字符。如果长度不够,可指定左填充的字符。默认是以空格左填充。
# rightpad: 右填充的字符。如果长度不够,可指定右填充的字符。
# config: 可以引用另外一个文件里面的定义。
# from: 引用某一个定义文件。
# use: 使用被引用文件中定义的若干实例。all代表使用所有。
# select: 如果引用的文件是excel表,可以查询里面的某一个字段。
# where: 如果引用的文件是excel表,可以使用查询条件。
# loop定义
# 可以使用一个数字来指定字段循环的次数,比如loop:2。
# 可以使用区间来定义字段循环的次数。比如loop:2-10。
# range定义
# 使用逗号连接不同的元素。比如 range: 1,2,3。
# 元素也可以是一个区间。比如 range:1-10, A-Z。
# 区间可以通过冒号:来指定步长。比如 range:1-10:2。
# 步长可以是小数。比如 range: 1-10:0.1。
# 步长可以是负数。比如 range:100-1:-1。
# 区间可以通过R来指定随机。比如 range: 1-10:R,随机和步长只能二选一。
# 可以通过一个文件来指定列表。比如range: list.txt。文件名是相对路径时,以配置文件为基准计算。
# 可以通过{n}的方式来重复某一个元素。比如 range: user1{100},user2{100}
# 如果区间或者几个元素需要重复,需要用[]括起来。比如 range: [user1,user2,user3]{100}
author: zentao
version: 1.0
fields:
- field: field_common # 默认的列表类型,通过逗号隔成若干区段。
range: 1-10, 20-25, 27, 29, 30 # 1,2,3...,10,20,21,22...,25,27,29.30
prefix: int_ # 前缀
postfix: "\t" # 后缀,特殊字符加引号,否则无法解析。
- field: field_step # 区间可以指定步长。
range: 1-10:2, 1-2:0.1 # 1,3,5,7,9,1, 1.1,1.2...,2
postfix: "\t"
- field: field_random # 通过R属性指定随机。R属性和步长不能同时出现。
range: 1-10:R # 1,5,8...
postfix: "\t"
- field: field_file # 从一个文件中读取列表,并指定随机。
range: users.txt:R # 该文件中一行作为一个元素,并随机。
postfix: "\t"
- field: field_loop # 自循环的字段。
range: a-z # a_b_c | d_e_f | g_h_i
loop: 3 # 循环三次
loopfix: _ # 每次循环的连接符。
postfix: "\t"
- field: field_repeat # 通过{}定义重复的元素。
range: user-1{3},[user2,user3]{2} # user-1,user-1,user-1,user2,user2,user3,user3
postfix: "\t"
- field: field_format # 通过格式化字符串输出。
range: 1-10 # passwd 1,passwd 2,passwd 3 ... passwd10。
format: "passwd%02d" # 用%2d补零,使密码整体保持8位,%2d默认补空格。
postfix: "\t"
- field: field_use_another_file # 可以引用其他的定义文件。
config: number.yaml # 引用当前目录下面的number.yaml文件里面的定义。
postfix: "\t"
- field: field_use_ranges # 引用內置的定义文件,该文件定义了多个range,他们共享了一些field层面的属性。
from: custom.test.number.v1.yaml # 引用data/custom/number/v1.yaml文件里面的ranges定义。
use: medium # 使用该文件中定义的medium分组。
postfix: "\t"
- field: field_use_instance # 引用其他的定义文件,该文件定义了多个实例。
from: system.ip.v1.yaml # 引用data/system/ip/v1.yaml
use: privateC,privateB # 使用该文件中定义的privateC和privateB两个实例。
postfix: "\t"
- field: field_nested_instant # 引用其他的定义文件,且该文件引用了其他实例。
# 引用data/custom/ip/private.yaml
use: all # 使用该文件中的所有实例。
prefix: "{"
postfix: "}"
- field: field_use_excel # 从excel数据源里面取数据。
from: system.address.v1.china # 从data/system/address/v1.xlsx文件中读取名为china的工作簿。
select: city # 查询city字段。
where: state like '%山东%' # 条件是省份包含山东。
limit: 10
postfix: "\t"
- field: field_with_children # 嵌套字段
fields:
- field: child1
range: a-z
prefix: part1_
postfix: '|'
- field: child2
range: A-Z
prefix: part2_
postfix: '|'
- field: child_with_child
prefix: part3_
postfix:
fields:
- field: field_grandson
prefix: int_
range: 10-20
postfix:
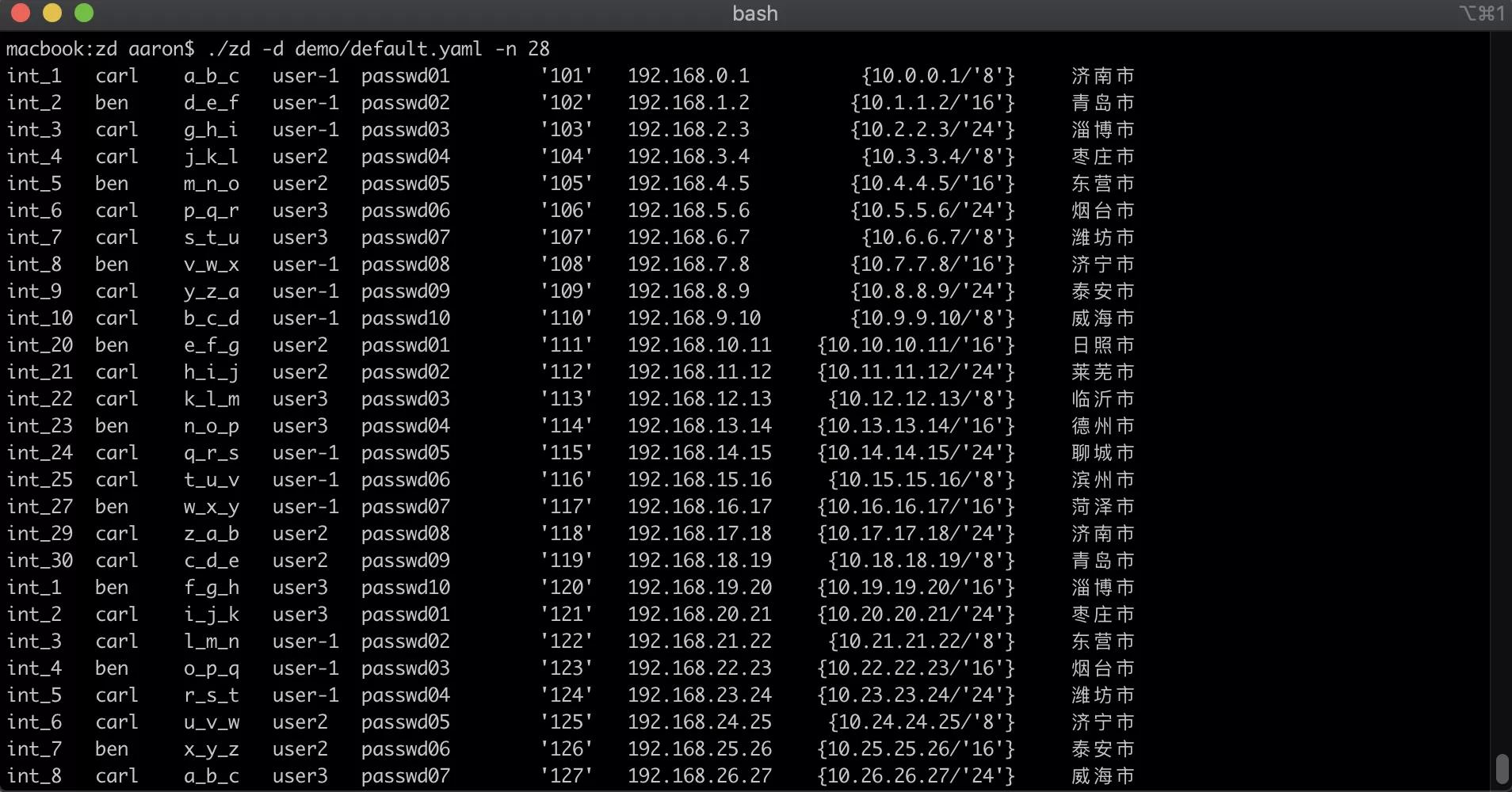
生成数据举例
下载地址

产品动态
